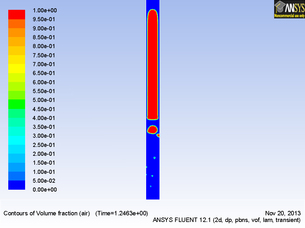
 Rising Taylor bubble in a vertical tube simulated using Ansys Rising Taylor bubble in a vertical tube simulated using Ansys The fantastic thing about modelling volcanic activity is that we can take our current understanding of the physics surrounding a volcanic problem and apply it safely at a desk. It may not be as exciting as being 'out in the field' but is certainly as valuable as we always need real world data to validate and verify models! Modelling activity takes many forms from investigating the dispersal of ash in the atmosphere for aviation, certainly a very prominent and current problem, to analysing potential lava flow paths, vital for determining potential construction sites. The other arguably most valuable thing about modelling is that it often enables us to see things that we otherwise wouldn't be able to view. For example sub-surface processes such as the motion of magma and gas beneath the surface, which just happens to be my modelling area. When involved with computational modelling, we try to constantly balance between levels of accuracy, an appropriate representation of the physics involved, computational power, solution time and storage space.
There are many excellent fluid dynamics software applications in existence, however, they are usually costly (running into the tens of thousands, notable exception here is OpenFoam). It is lucky therefore that the University of Sheffield has access to one of the leading applications Ansys and the dynamic Ansys Fluent package. Below is an example of Ansys Fluent model run, simulating the rise of a volcanic slug, generally believed to be the cause of strombolian eruptions at the such volcanoes as the archetypal Stromboli. Cheaper applications such as Matlab, certainly offer the ability to perform, less complex physics problems but lack the user-friendly interfaces such as Ansys and necessitate an in-depth knowledge of the maths and physics behind the problem! I am sure I have missed many considerations off here, but these are just a few tasters! It is vitally important that models are not just used on their own, as there is nothing to calibrate or validate the model against. The best way of modelling is by comparing observations in the field, in my case gas emissions, with laboratory proxies, and models. Anyhow, when weighing all of these points against the benefits, a clear and greater understanding of environmental processes is essential and is something which can only occur with significant modelling of processes. Below is an example simulation of a taylor bubble (or slug) rising through a tube as a proxy for the root cause of a strombolian eruption (the type seen at stromboli). Comments are closed.
|
 Archives
July 2023
|
 RSS Feed
RSS Feed